
19 Nov Data analytics, AI and ML demystified
In the past few years there has been an increase in the adoption and acceptance of artificial intelligence (AI) – if one adopts a broad definition of the term, that is. The field of AI encompasses everything from simple spellchecking, predictive text, ‘Because you watched…’ recommendations of video content, to complex machine learning (ML), predictive models and simulations.
However, within manufacturing there are still a lot of sceptics who do not understand the basics of AI and do not see how it can be beneficial for their facility. Where companies do understand the basics and benefits, adoption is still slow as the next question is often (as with anything new): where do we start and do we even have what it takes to begin?
So, what are data analytics, artificial intelligence and machine learning? Are they a silver bullet that will solve problems magically? Do you need a data scientist to be able to use these technologies? Where does one start on an analytics journey? Herein, we will try and answer these questions and provide some guidance for the (easier) adoption of AI and ML in the manufacturing and processing industries.
What happened?
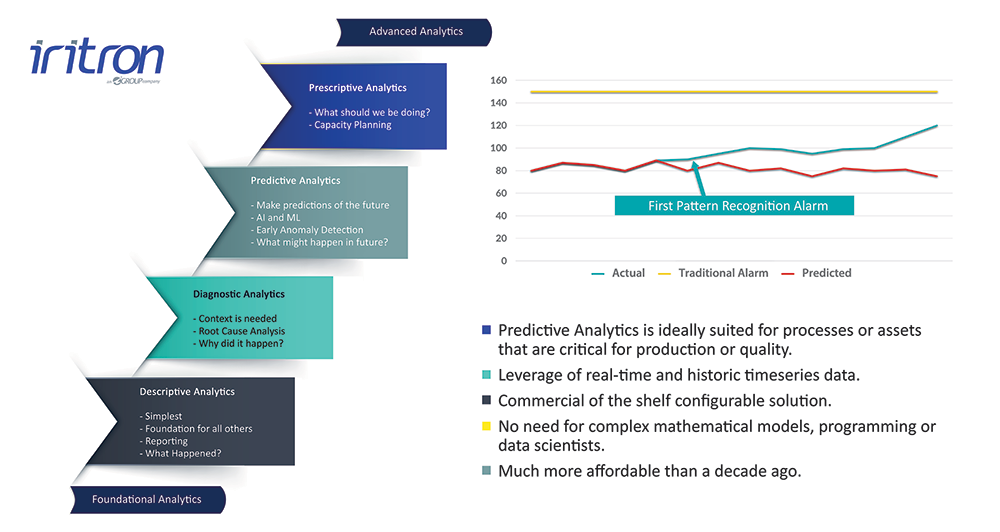
Figure 1 depicts data analytics as a continuum ranging from foundational analytics to advanced analytics, and includes descriptive, diagnostic, predictive and prescriptive analytics. Descriptive analytics forms the basis for all other analytics categories. Most companies already have descriptive analytics implemented as it answers the question ‘what happened?’ Software technologies supporting descriptive analytics include plant historians that can record a large number of plant parameters every time the values of the parameters change.
Time series data comprises a date and timestamp, and the process value. Time series data is used to find out and report on what happened before and after a deviation occurred. Time series data also forms the basis for industrial AI and ML (more about this later).
Other technologies that enable descriptive analytics include manufacturing operations management (MOM) systems. For example, transactional records on material and product movement throughout the manufacturing value chain, the related quality samples and their results, plant throughput compared to the plan, and reasons for plant downtime for a specified period, amongst others. MOM technologies typically include comprehensive reporting to be able to answer the ‘what happened’ question.
Why did it happen?
The next step in the continuum is diagnostic analytics and this answers the question ‘why did it happen?’. Additional context is normally needed to answer such questions. Root cause analysis tools that are bundled together with plant historians allow for the analysis of data by trending various process variables together and viewing the values in relation to one another on the same time axis. This makes investigation of process anomalies by process engineers possible, allowing them to understand why things happened in a certain way at a given moment in time.
MOM systems are also powerful for providing context as they provide time and transactional views related to production, inventory, quality and maintenance. This context allows the user to gain a deeper understanding of and insight into plant or facility performance. A simple example is looking at production numbers together with shift information, allowing the user to compare performance between dayshifts and nightshifts. Other context categories include product, plant, production line, quality, throughput and seasons, to name a few.
What might happen in future?
The next step in the continuum is predictive analytics, which answers the question ‘what might happen in future?’. Predictive analytics is typically based on AI and ML technology and needs the same time series historical data introduced above for descriptive analytics.
Predictive analytics is ideally suited for processes or assets that are critical for production or quality, or assets which are capital-intensive and critical for plant throughput. Commercial off-the-shelf AI and ML solutions do exist, and it is thus not necessary to understand complex mathematical models or be a data scientist to use the technology. Understanding the plant process and which process variables are important for production, quality and asset health is, however, very important.
Cloud technology makes AI and ML much more affordable and viable than a decade ago. Cloud technology makes it more viable to increase processing power for short periods of time (during the data processing and model development phase) without the need to purchase the processing power infrastructure for on-site deployment. There are various OEM technology suppliers offering configurable advanced pattern recognition (APR) and early anomaly detection (AI and ML) systems in the industrial marketplace today.
Typically, a process or asset is modelled by using related process variables and historical time series data to find patterns related to different operating conditions. After modelling a process (based on historical patterns), the model is deployed and compared to what is happening in real time on the plant to predict when an anomaly might occur. These models can predict a potential future event long before traditional supervisory control and data acquisition (scada)-type alarming will be triggered.
Predictive analytics aims to prevent costly breakdowns or poor quality by identifying deviations and anomalies early, when timely intervention can still affect the outcome. For instance, if a machine is predicted to break down three weeks from now, you can do an organised, planned shutdown two weeks from now to prevent a costly breakdown and adverse plant conditions.
What should we be doing?
The last step is prescriptive analytics. Prescriptive analytics answers the question ‘what should we be doing?’. One technology that assists with this is finite capacity scheduling. If a production process consists of many steps, and parallel and serial paths, devising the optimum schedule can be difficult, especially for large quantities of orders and stock keeping units (SKUs).
It is important to take production capabilities, setup times, changeover times, the need for cleaning in place (CIP) and scheduled, planned maintenance into consideration. Typical ERP and MRP systems find it difficult (or too expensive) to model plants to a level of detail required to provide an effective schedule based on actual capacity and constraints, as opposed to infinite capacity.
It also becomes very important to know what happened to orders that were supposed to be processed, as this directly impacts the schedule going forward. This shows again that the foundational analytics need to be in place to know what happened to planned orders before one can successfully implement prescriptive analytics in terms of planning into the future.
Various MOM systems provide planning and scheduling tools, ranging from comprehensive finite capacity scheduling systems to more basic scheduling tools, but all tools aim to assist in answering the question of what one should be doing to make optimum use of plant capacity.
Scheduling can be done based on predetermined scenarios, such as maximising equipment utilisation, minimising late orders or maximising profit, amongst others. Some of these may be mutually exclusive, but in some cases one can combine two or more rules where one rule takes precedence, and the next rule is applied to the result of the first rule. For instance, if our first rule is ‘minimise late orders’, we can take that result and apply the ‘maximise equipment utilisation’ rule to the result. If we do it the other way around, we will get a different schedule.
Other technology that can assist in answering the ‘what should we be doing?’ question is smart KPIs and dashboards, in combination with high-performance graphics. Dashboards and smart KPIs are aimed at highlighting any condition that develops which can negatively impact quality or production, and thereby guide the user to focus their attention and response on the issue or abnormal condition that needs to be responded to, so as to maintain operational excellence.
The concept of a digital twin has been popularised in the past few years. This is where a piece of equipment or process is designed in digital form to react the same way as the physical equipment or process given the same (digital) inputs. This digital twin of the physical system can be designed using first principles or by using historical data.
Once the digital twin has been developed and proven to be accurate when run in parallel with the physical twin, it can be used to not only show what might happen in future if no action is taken, but can also provide the ability to run different ‘what if?’ scenarios to find the best ‘what should we be doing?’ answer.
Closing remarks
In conclusion, we believe we have provided a short explanation of data analytics, AI and ML. We showed that they are not a silver bullet that will solve problems magically, and that you do not need a data scientist to start on the journey. To answer the ‘where does one start with an analytics journey?’ question, we believe that we showed how one can progress from normal ‘what happened?’ reporting to a situation where you can use the data available in your plant to answer the ‘what should we be doing?’ question.
For more information contact Neels van der Walt, Iritron, +27 83 387 7559, neels.vanderwalt@iritron.co.za, www.iritron.co.za